How to Uncover Non-obvious SEO Mistakes on Gatsby Websites

Monica Lent published

I want to start by dislodging perhaps the most prevalent misunderstanding about SEO that developers have today:
The idea that making a website "SEO-friendly" is primarily about having some meta tags in the head of your website.
You can read just about any JavaScript blog on the SEO aspect of popular libraries or frameworks, whether it's Gatsby, React, NextJS, or Vue. The content centers around just a few items. Namely:
- Populating some meta tags (incl. the canonical tag)
- Rendering a sitemap
- Maybe structured data, too
Yes, having a title, description, canonical tags, and other meta tags are important.
But the problem is, no one bothers to explain to developers why those things are important or how they're used.
So those initial SEO efforts often become broken over time, as an unintended side effect of other changes on a website. And since the devs don't know the mechanics behind it, they never notice.
That is, until the CEO freaks out that the website "isn't on Google anymore".
So today, I want to help you find and fix these non-obvious issues that could be hurting how well your site is being discovered in search 🎉
In case you're wondering: Why talk about SEO with Gatsby in particular? For me, it's three reasons:
- The "magic of Gatsby" makes this framework prone to these issues
- Lots of developers use Gatsby for their personal or project blogs
- I recently audited one of my Gatsby sites and was surprised to find tons of mistakes (so, even as someone who knows this stuff, it is really easy to miss!)
That said, these issues can apply to any website on the planet. So even if you don't use Gatsby, you'll still find practical ways to recognize technical SEO issues on websites written with other frameworks.
In this post you will learn:
- What is technical SEO and why should I care?
- Tactics for finding and fixing Gatsby SEO mistakes (and why they are problematic)
- More resources for learning about technical SEO
What is technical SEO?
By definition, technical SEO is the aspect of SEO that ensures your website can be effectively crawled, rendered, and indexed by Google.
Often, Google is smart enough to figure out what's going on, but other times mistakes can lead to a page or website not ranking as well as it could, or for pages not to get indexed.
There are many other aspects to SEO such as keyword research, the content itself, accumulating backlinks and building your website's authority, and so forth.
Why should you care? At least for developers who subscribe to my newsletter, SEO matters because they want to get more people to visit their blog or their online business without spending money on ads or having a massive social media following.
Gatsby SEO mistakes: tactics for finding and fixing them
I need to emphasize that this list is not exhaustive.
But I picked these issues to focus on because they all represent pitfalls that I believe are probably really common in the Gatsby world (especially if you don't have a dedicated SEO expert handling the website).
We're going to look into:
- Orphan pages in
src/pages - Accidentally indexable draft content
- Duplicate content for generated pages
- Non-redirected, inconsistent trailing slashes
- Inconsistent trailing slashes and canonicals from internal links
I even have one example of an minor issue I found on the official Gatsby website, which just goes to show how tricky this stuff can be.
1. Orphan pages in src/pages
Orphan pages are pages on your website that don't have any internal links to them.
And because of the fact that Gatsby automatically creates pages for everything inside your src/pages,
it is extremely easy to accidentally end up with orphan pages.
(Especially because a lot of developers are afraid to delete things, "just in case" we might need it later 😉)
While orphan pages aren't necessarily bad in terms of SEO, they can be a sign of other issues. Imagine this scenario:
- It's a page you're not updating anymore
- You don't link to it from anywhere in the site
- But it's still in your sitemap
This can result in your visitors finding outdated content by searching for it in Google. Not necessarily, but it can happen.
Detect it: Check your sitemap or use a crawler
If you have a small site, you can literally just open up your sitemap and look at it, usually at /sitemap.xml.
You might immediately find pages you don't want indexed (on my site I found an outdated FAQ and Contact page).
Without a sitemap, you can check in the build/ directory.
If you have a bigger site that is impactical or impossible to check manually, there are tools that will detect orphan pages for you though a lot of them are paid. Screaming Frog is one tool that's popular with people who do SEO for a living.
I first noticed I had some orphan pages after running the Ahrefs Site Audit tool.
Solution: Delete or exclude the excess pages
The easiest thing to do is just to delete those pages.
Another option is that you can use something like the gatsby-plugin-exclude plugin to exclude those pages from being rendered.
While you're looking in your sitemap, you might find other things you don't expect to be there...
2. Accidentally indexable draft content
These are also orphan pages, but with a different root cause.
You may have something like unpublished blog posts showing up in your sitemap, and even getting built.
But you might not see that if you're doing your filtering in your React components
rather than when the pages are build in gatsby-node.js.
Imagine this common scenario:
- Your
gatsby-node.jspulls all Markdown files fromsrc/pages/blog/posts/ - Your blog index page on
src/pages/blog/index.jsqueries for the markdown - You filter the published posts on the client-side by checking for a field like
draft: false(or perhaps as part of your query) - You don't see those posts on your index, but they are still built by Gatsby (and still in your sitemap)
You might not think twice about doing the filtering on the client (as is second nature for a frontend developer) — but this is what happens :)
Detect it: Check your build directory for draft content
Look inside the build directory and just see whether somewhere like build/blog/ also
contains content you don't expect it to, such as the drafts you're currently working on.
Again, this will come up if you use a tool like Screaming Frog or a Site Audit tool.
Solution: Filter content during the build phase
Make sure that you check if something should be built inside gatsby-node.js instead of on the client.
Like below in createPages, I'm only querying for posts where the date in the frontmatter is
not an empty string.
exports.createPages = async ({ actions, graphql }) => {
const { createPage } = actions;
const blogPostTemplate = require.resolve(`./src/templates/BlogPost.tsx`);
/*
* In this example, I'm assuming that posts without a date set are drafts.
* You could also use your own flag like `draft: true` or some other mechanism.
*/
const result = await graphql(`
query {
allMdx(filter: { frontmatter: { date: { ne: "" } } }) {
edges {
node {
id
fields {
slug
}
frontmatter {
title
date
}
}
}
}
}
`);
if (result.errors) {
reporter.panic('Error loading data to create pages', result.errors);
return;
}
const posts = result.data.allMdx.edges;
// Create pages for each blog post
posts.forEach(({ node }) => {
createPage({
path: node.fields.slug,
component: blogPostTemplate,
context: {
postId: node.id,
},
});
});
};
But alas, getting rid of excess pages in src/pages AND ensuring no drafts are
generated in gatsby-config.js are STILL not enough to ensure we don't have rogue content going live.
There is yet ANOTHER WAY to accidentally end up with orphan pages with Gatsby.
And it's arguably the most problematic.
3. Duplicate content for generated pages
According to Google, we should not have duplicate content on our websites.
What does that mean? It's when, "substantive blocks of content within or across domains that either completely match other content or are appreciably similar."
You might think this couldn't apply to you because you don't copy/paste on your website.
However, if you are using something like gatsby-plugin-filesystem and gatsby-plugin-mdx
(or the markdown equivalent) to generate pages, you might find that the unparsed pages
are being built and published IN ADDITION to the ones that look beautiful and are linked from your
website.
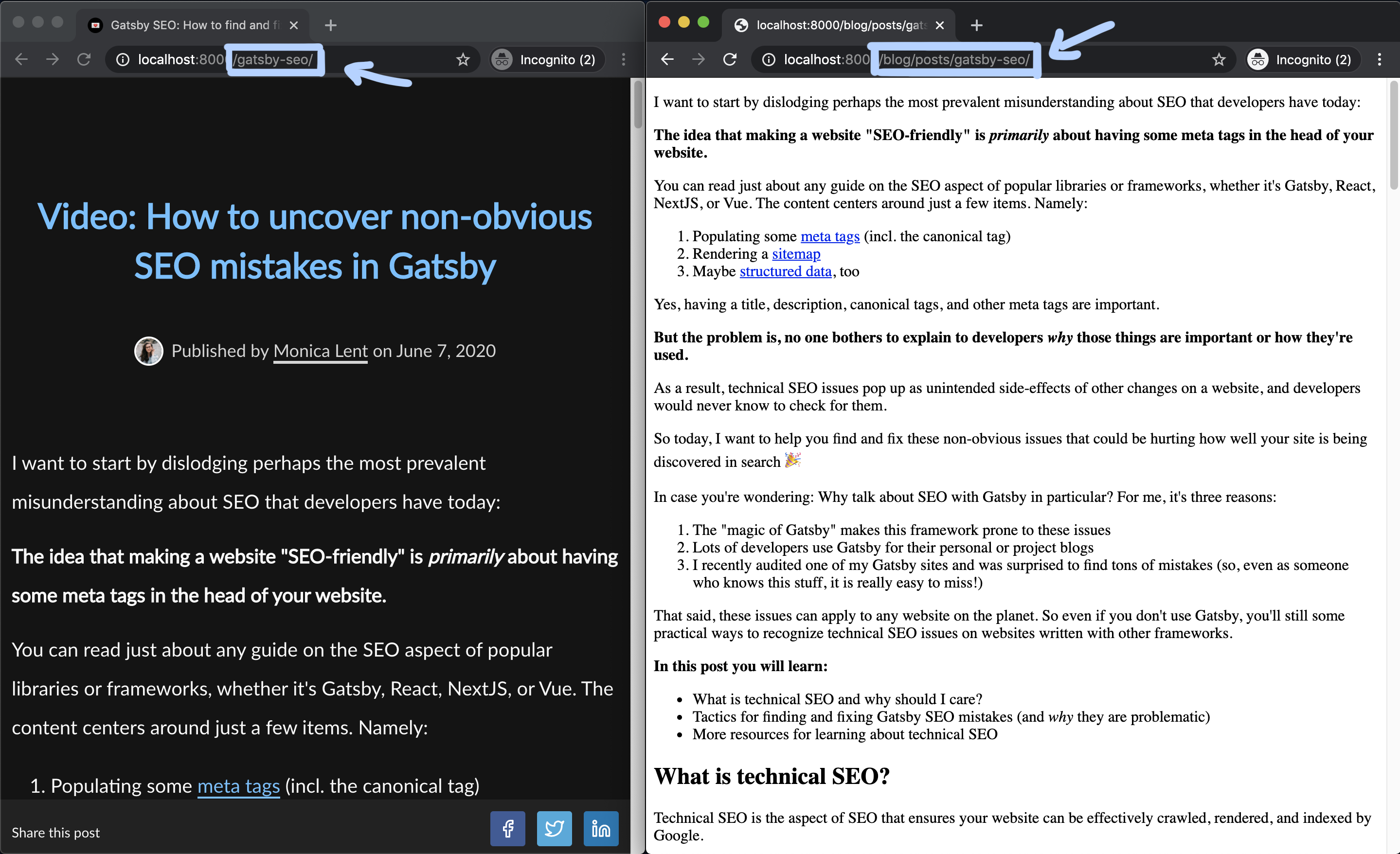
This is slightly disturbing, right?
On the left, you can see my desired URL /gatsby-seo/, and on the right, /blog/posts/gatsby-seo/
which corresponds to the file path of the mdx file.
The additional reason this is a problem is that if I look at the canonical URL for the "ugly version",
I can see it has a unique canonical URL, because it's being added by gatsby-plugin-canonical-urls.
Solution: Exclude the pages from the normal build process
First off, I ended up getting rid of gatsby-plugin-canonical-urls. I'd rather have more fine-grained
control over making sure my canonical URLs are being properly rendered.
As for ensuring that the raw version of the file isn't rendered, I'm not sure what the "right way" is officially. I can see a few options:
- Move your posts outside of
src/pagesinto a parallel directory likesrc/content - Use the
gatsby-plugin-excludeplugin to prevent the ugly versions from being built
I personally like having everything inside src/pages so I've added this plugin configuration to my
gatsby-config.js setup:
{
resolve: 'gatsby-plugin-exclude',
options: { paths: ['/blog/posts/**'] },
},
Make sure you verify the fix by both checking the build directory AND checking your sitemap.xml.
4. Non-redirected, inconsistent trailing slashes
Inconsistent trailing slashes just means that you may have the ability to access (without being redirected) a version
of a page like /path-to-my-path/ and /path-to-my-page. The reason is that Google treats pages with and without
a trailing slash as two different pieces of content, particularly if they do not share the same canonical URL.
Funny enough when I was just checking out the official Gatsby website's sitemap, I noticed a set of URLs that lacked a trailing slash (almost all pages do have a trailing slash):

In this situation, the first thing to check is that if I open /blog what will I get. Will I be redirected to the version
with the slash? Or, if no redirection occurs, will I have two separate pages — one with and one without?
In this case, it redirects me:
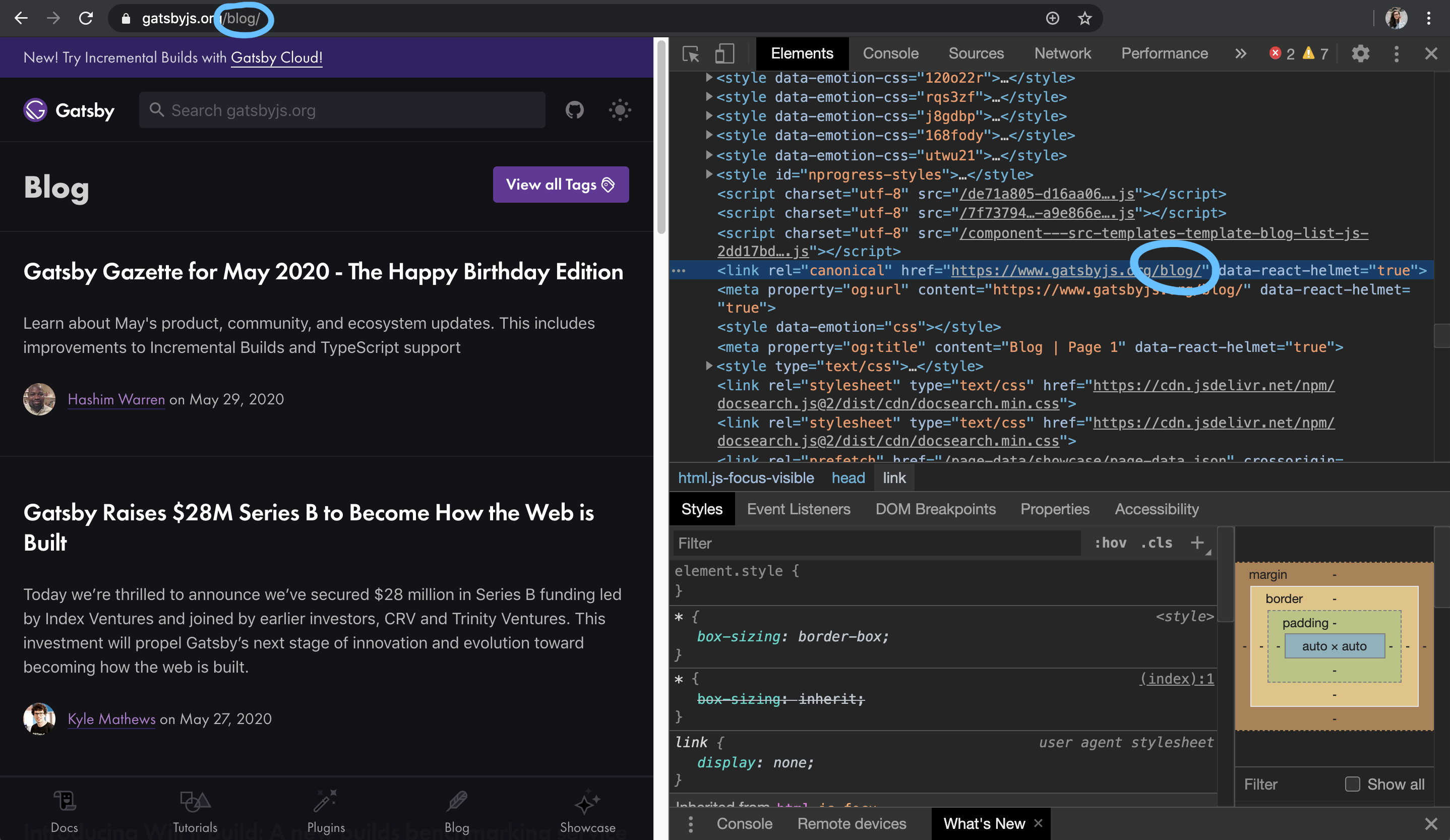
And the trailing slash is forced server-side with a 301 redirect.
Which is a good thing, because it ensures a single canonical URL for the piece of content.
(Interestingly, it does exactly the opposite for /blog/page/2 and strips the slash)
Yet, the version of /blog without the slash made it into the sitemap, despite not being the canonical URL.
This is most likely a really tiny bug, and is not actually a big deal.
The point I want to make is just that it is so easy to end up with inconsistent trailing slashes. So if the pros can experience this, so can the rest of us.
When is this actually a problem? Looking at this example, it would've been an issue if:
- There was no 301 redirect from
/blogto/blog/ - We could load both
/blogand/blog/separately - AND both pages had their respective, different values for the canonical URL
Now, there is another Gatsby-flavored twist to this issue which is pretty interesting, and that has to do with how Gatsby's <Link> component works.
This is a really interesting issue which is somewhat "unique" to Gatsby websites, given the mix of client and server-side navigation.
5. Inconsistent trailing slashes and canonicals from internal links
So you're feeling pretty responsible because you implemented an Nginx rule to redirect URLs
that look like /something to /something/.
But can you imagine what happens if you type this code inside a component?
<Link to="/something">My internal link</Link>
Because of the fact that, after loading the page, you're in the world of client-side routing, your server-side redirect has no effect.
That means that you might end up with the same content with and without a trailing slash in the canonical URL depending on if you navigated internally or via the browser.
Yikes.
This is where it becomes important to know that the main way Google understands your website is by crawling internal links.
Even if you submit your sitemap to Google Search Console, Google still want to understand your site's structure and internal links.
Detect it: Crawl your site
The easiest way to find this is by crawling your website using a tool such as Screaming Frog or Sitebulb.
However, if your website is really small, you can probably discover this through internal links. Just search for everything via Grep:
grep -r '<Link' .
And look for <Link> components whose to= parameters do not have a trailing slash.
Another, unfortunate way to discover this is by finding inconsistent URLs in Google Search Console.
Solution: Audit all your internal links
Go in and add any missing trailing slashes. And make sure your client and server-side behavior is consistent.
Another way of doing this is by creating a constant with your routes instead of allowing devs to type them by hand. For example:
const ROUTES = {
HOME: '/',
PRICING: '/pricing/`,
CONTACT: '/contact/'
};
This can help keep things consistent. Just make sure that when you have dynamically built URLs, you're also handling that. For instance:
const ROUTES = {
HOME: {
toUrl: () => '/'
},
BLOG_POST: {
toUrl: slug => `/blog/${slug}/`
}
};
That way, in your <Link> component, you can use something like:
{posts.map(post => (
<Link to={ROUTES.BLOG_POST.toUrl(post.slug)}>{post.title}</Link>
))}
This can help ensure that your internal trailing slashes are correct, and you never lead someone to a client-side rendered route that results in an incorrect canonical URL.
Is it a little dry? Kind of! But it's important to get out of the way :)
More resources for learning about technical SEO
- Blogging for Devs Newsletter — The website you're reading now is the primary home for my newsletter that teaches blogging and SEO to developers, based on my experience building a blog that's reached over a million visitors.
- Backlinko's Technical SEO Guide — This guide goes deeper into how search engines find, crawl, render, and index pages on your site. You can learn more about how Google's crawler actually works.
Do you think your friends or followers would find this blog post helpful? I'd love it if you could share it on Twitter or send it to your colleagues!
You don't have to be Twitter-famous to grow your blog as a developer.
Take the FREE 7-Day Blogging for Devs Email Course and learn how to grow your blog without an existing audience (!) through great writing and SEO.
Learn how to grow your blog as a developer without an existing audience through great writing and SEO.